

Algorithm: leetcode 57 - Insert Interval.
Review: Build Experience Faster for Career/Promotion
Tips: Hide Your Password from CLI in Env Var
Share: Release Our Change on Production under Modern Procedure
Algorithm: leetcode 57 - Insert Interval.
Divide into three cases:
Without overlap
Insert before an interval
Insert after an interval
With overlap
Redefine a new interval to insert
func insert(intervals [][]int, newInterval []int) [][]int {
output := [][]int{}
for idx, interval := range intervals {
if newInterval[1] < interval[0] {
output = append(output, newInterval)
return append(output, intervals[idx:]...)
} else if newInterval[0] > interval[1] {
output = append(output, interval)
} else {
newInterval = []int {
min(newInterval[0], interval[0]),
max(newInterval[1], interval[1]),
}
}
}
output = append(output, newInterval)
return output
}Review: Build Experience Faster for Career/Promotion
tl;dr To sum up, two ways:
1. (Obviously) Work a lot of extra hours which allows to pursue multiple workstreams at the same time,
2. Think two levels ahead to skip sustain phase when we try to get used to the next level behavior
Work More/Longer
Doing a larger volume of work at the next level’s expectations helps us build a track record fast.
⇒ This could give the manager enough evidence/content for the promotion packets.
P.S. The writer often had an extra workstream or two outside of his main work. (50-60 hours per week)
A Long-term Thinking - Think Two Levels Ahead
Every promotion has two high-level phases that depend on each other:
Growth Phase (Green) - Grow into the next level’s behavior
Sustain Phase (Yellow) - Keep up those behavior, which really starts to build the necessary track record.
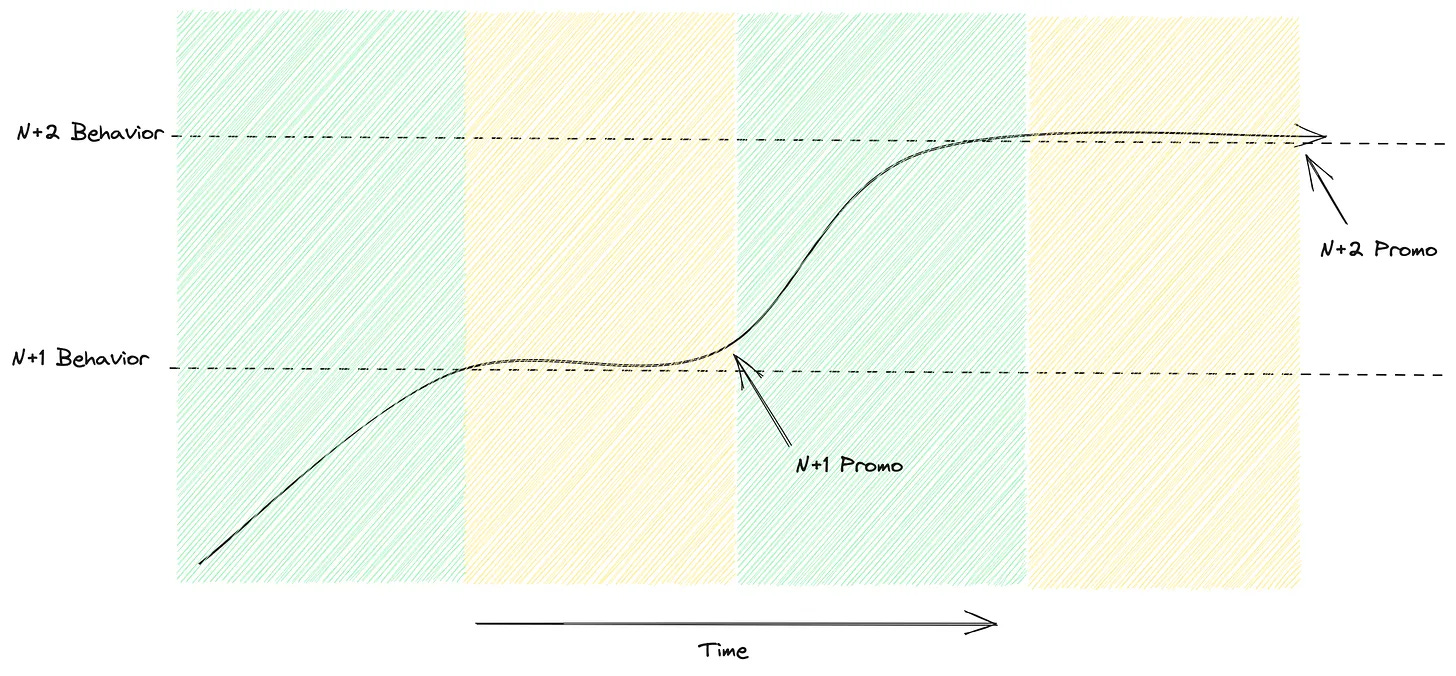
It’s faster to skip the sustain phase(N+1 promotion) by starting to grow behaviors towards N+2 behaviors.
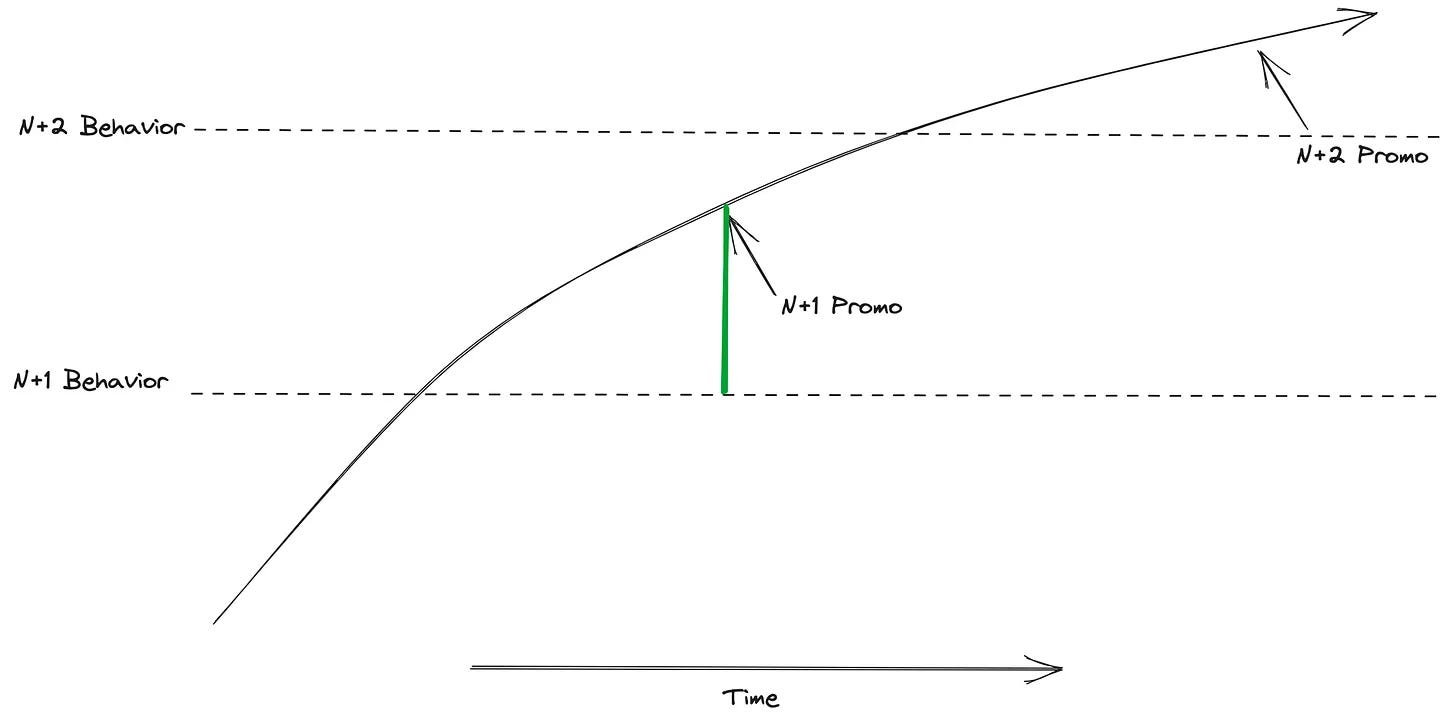
Ref
Tips: Hide Your Password from CLI in Env Var
It’s always safer to keep the encoded password on your PC.
I have this code snippet in .zshrc to decode the encoded password, and keep the result as an environment variable.
# .zshrc
decode() {
strg="${*}"
printf '%s' "${strg%%[%+]*}"
j="${strg#"${strg%%[%+]*}"}"
strg="${j#?}"
case "${j}" in "%"* )
printf '%b' "\\0$(printf '%o' "0x${strg%"${strg#??}"}")"
strg="${strg#??}"
;; "+"* ) printf ' '
;; * ) return
esac
if [ -n "${strg}" ] ; then decode "${strg}"; fi
}
decoded_value=$(decode "$ENCODED_PASSWORD")
export PROXY_PASSWORD="$decoded_value"Share: Release Our Change on Production under Modern Procedure
This a standard procedure to release change on production in my mind:
Running a series of unit tests to make sure the internal logic goes right
Build up a new docker image
Apply the new image to staging environment
Running test cases in staging environment
Apply the new image to production environment
Wait and see the production running status
And it’s possible to make them all run automatically with scripts and GitHub Action.
However, I like the way my current company(FLYWHEEL) do (around data pipeline), which is based on lots of infrastructure efforts:
Have a PR to change the image tags(staging, qa, production)
Manually apply the change to staging first
Run a specific series of test cases in staging so that to make sure the change won’t break the existed features. This is not a perfect solution to test but is workable to some extent. Not necessary to achieve the best at first
We left the test results in GitHub PR page, so it’s trackableThen apply the change to qa first if we need to run other specific test to validate the change. So that we don’t pollute the job history in production but are able to validate with real data.
At the end, apply the change to production, and wait to see the production running status.
Feel free to come up with the discussion about better practice.